Una de las cosas más importantes que vas a tener que hacer al montar tu servidor local, es controlar el buen estado de tu Mini PC y de todo su software instalado con Docker. Lo bueno, es que estamos cubiertos con dos programas, Netdata y Scrutiny. Netdata es una suite Open Source para monitorear todo tu Mini PC (discos duros, RAM, GPU, contenedores Docker…), mientras que Scrutiny es un sencillo programa que nos permite controlar la salud de nuestros discos duros. Dos enfoques muy diferentes. Ambos son gratuitos.
Básicamente, con estos dos programas vas a conseguir no perder todos los datos que tengas almacenados en tu servidor local (¡ojo! No se te olvide configurar un buen backup en tu servidor).
¿Son complicados de instalar? No, para nada, pero Netdata probablemente ofrezca más datos de los que quieres asimilar en un principio, algo que no pasa con Scrutiny.
Te recomiendo empezar con Scrutiny, que va a avisarte de posibles errores y fallos en tus discos duros, y luego ampliar tu seguimiento con Netdata.
¿Qué necesitas antes de empezar? Tener tu Mini PC con Linux, Docker, Docker Compose y Portainer (opcional). Si quieres conectarte a Scrutiny desde fuera de tu red local (fuera de tu casa, por ejemplo), vas a tener que configurar en tu Mini PC y en tu móvil (por ejemplo), la app Tailscale (gratis), que se instala de manera muy sencilla. Así evitas exponer Scrutiny directamente a internet y no tienes que configurar un reverse proxy. Tampoco necesitas HTTPS con certificados SSL. En el caso de Netdata, al darte de alta en su plan gratuito, puedes acceder desde cualquier sitio tus datos a través de app.netdata.cloud.
Sigue estos pasos:
- Consigue un Mini PC e instala Linux y Docker: Es suficiente un modelo con un chip sin demasiadas pretensiones como el Intel N100 o el N150. Con 16 GB de RAM tienes de sobra. Necesitas un disco SSD para el SO y tus contenedores Docker y un HDD para tus datos más pesados. Por menos de 130 euros tienes muchos modelos en AliExpress.
- Configura Docker correctamente con backups y reinicio automático para no llevarte una sorpresa después de pasarte horas configurándolo todo.
- Configura los backups de Linux Mint con TimeShift (incluye tu carpeta home).
- Sigue esta guía para instalar Scrutiny y Netdata.
Configuración de Scrutiny para controlar la salud de tus discos duros
Con Scrutiny vas a controlar la salud de tus discos duros gracias a S.M.A.R.T y el daemon smartd. Scrutiny es una aplicación sencilla pero específica, con estas características principales:
- Panel de control de la interfaz de usuario web: centrado en métricas críticas.
- Integración con smartd.
- Detección automática de todos los discos duros conectados
- Seguimiento de métricas S.M.A.R.T para tendencias históricas
- Umbrales personalizados
- Seguimiento de la temperatura
- Alertas/notificaciones configurables a través de webhooks
Scrutiny lo vas a tener que instalar en un contendor Docker, que ya tienes puesto en marcha. Me he decantado por instalar 3 imágenes en su versión Hub/Spoke.
Puedes usar Docker Compose (docker-compose.yml). Esto es lo que he utilizado yo, copiando y pegando esta información en un nuevo Stack en Portainer:
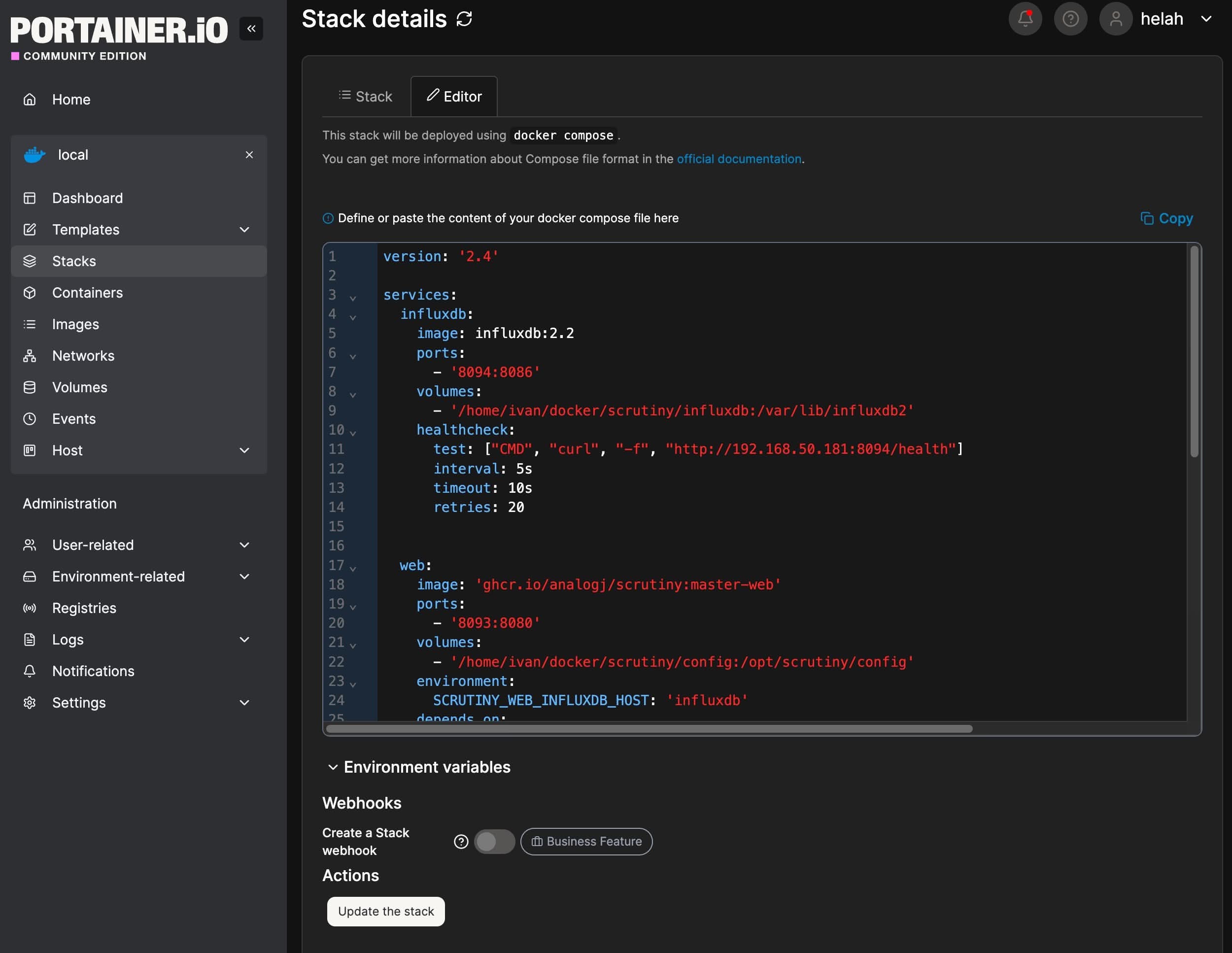
version: '2.4'
services:
influxdb:
image: influxdb:2.2
ports:
- '8086:8086'
volumes:
- './influxdb:/var/lib/influxdb2'
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8086/health"]
interval: 5s
timeout: 10s
retries: 20
web:
image: 'ghcr.io/analogj/scrutiny:master-web'
ports:
- '8080:8080'
volumes:
- './config:/opt/scrutiny/config'
environment:
SCRUTINY_WEB_INFLUXDB_HOST: 'influxdb'
depends_on:
influxdb:
condition: service_healthy
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/api/health"]
interval: 5s
timeout: 10s
retries: 20
start_period: 10s
collector:
image: 'ghcr.io/analogj/scrutiny:master-collector'
cap_add:
- SYS_RAWIO
volumes:
- '/run/udev:/run/udev:ro'
environment:
COLLECTOR_API_ENDPOINT: 'http://web:8080'
COLLECTOR_HOST_ID: 'scrutiny-collector-hostname'
# If true forces the collector to run on startup (cron will be started after the collector completes)
# see: https://github.com/AnalogJ/scrutiny/blob/master/docs/TROUBLESHOOTING_DEVICE_COLLECTOR.md#collector-trigger-on-startup
COLLECTOR_RUN_STARTUP: false
depends_on:
web:
condition: service_healthy
devices:
- "/dev/sda"
- "/dev/sdb"¿Qué tienes que cambiar?
- En volumes puedes poner una ruta específica a tus datos:
- /ruta/a/influxdb:/var/lib/influxdb2
- /ruta/a/config:/opt/scrutiny/config
- En vez de usar localhost en las URL, siempre pongo la IP de mi servidor local. consultalo en tu router.
- En devices, tienes que poner las rutas a tus discos duros. Pones en Terminal df -h y te saldrá el listado:
- «/dev/sda»
- «/dev/sdb»
- «/dev/sdc»
Cuando tengas eso cambiado, ya puedes crear el nuevo Stack y ponerlo en marcha. Ahora solo tienes que ir a la dirección url indicada en la configuración, en mi caso: http://192.168.50.181:8093 (cambia la IP por la que tenga tu servidor local).
También puedes utilizar estos comandos Docker en el terminal:
docker run --rm -p 8086:8086 \
-v `pwd`/influxdb2:/var/lib/influxdb2 \
--name scrutiny-influxdb \
influxdb:2.2
docker run --rm -p 8080:8080 \
-v `pwd`/scrutiny:/opt/scrutiny/config \
--name scrutiny-web \
ghcr.io/analogj/scrutiny:master-web
docker run --rm \
-v /run/udev:/run/udev:ro \
--cap-add SYS_RAWIO \
--device=/dev/sda \
--device=/dev/sdb \
-e COLLECTOR_API_ENDPOINT=http://SCRUTINY_WEB_IPADDRESS:8080 \
--name scrutiny-collector \
ghcr.io/analogj/scrutiny:master-collector¿Qué es lo que te vas a encontrar al ir a esa URL?
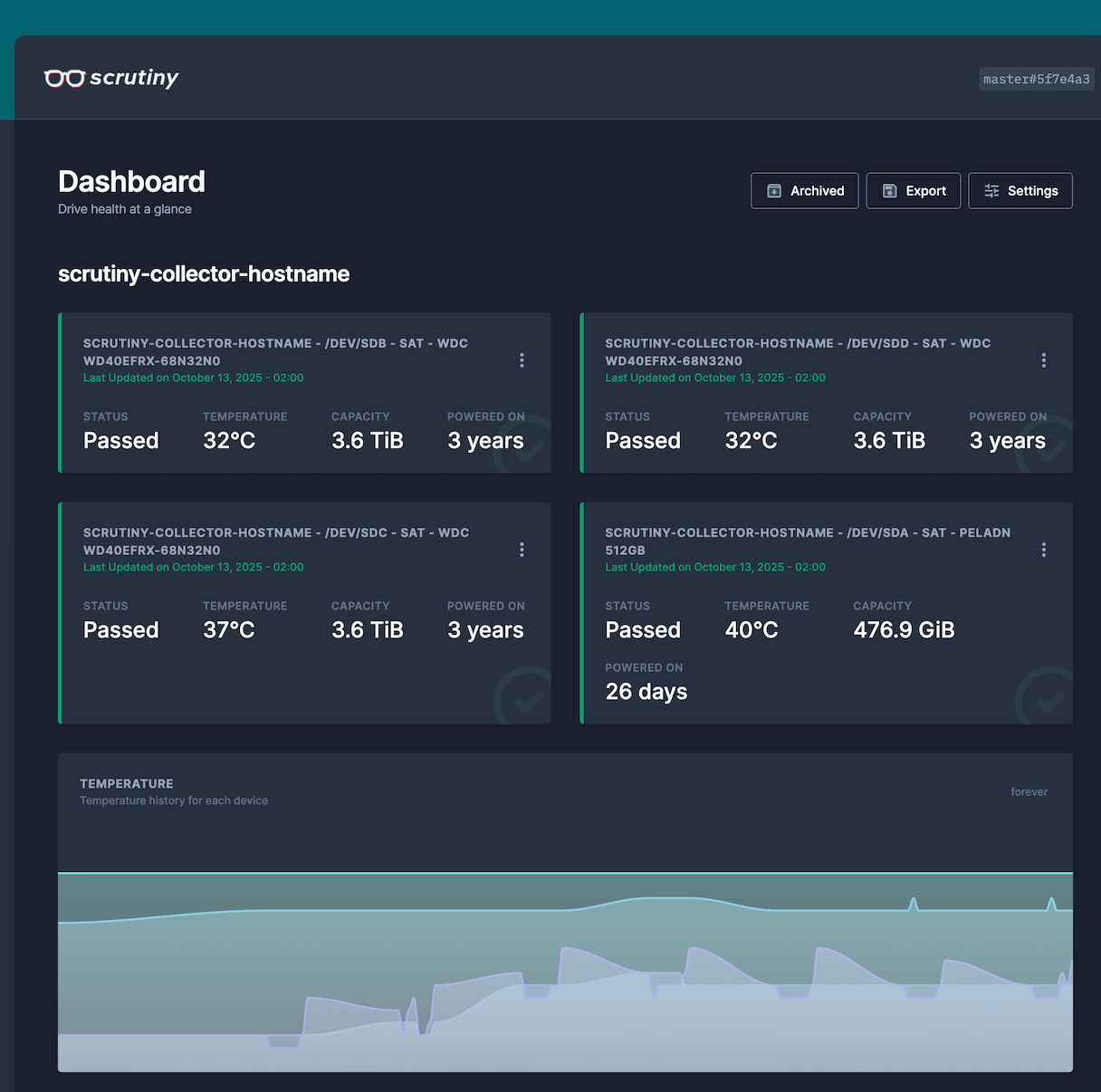
Los datos más importantes de salud de tus discos duros configurados y conectados en tu mini PC.
- Si ha pasado los test
- Temperatura
- Capacidad
- Años que llevas usando los discos.
Si pinchas en los tres puntos, entrarás a consultar en detalle todos los test que ha pasado el disco todas las noches (el cron se activa de forma automática todos los días).
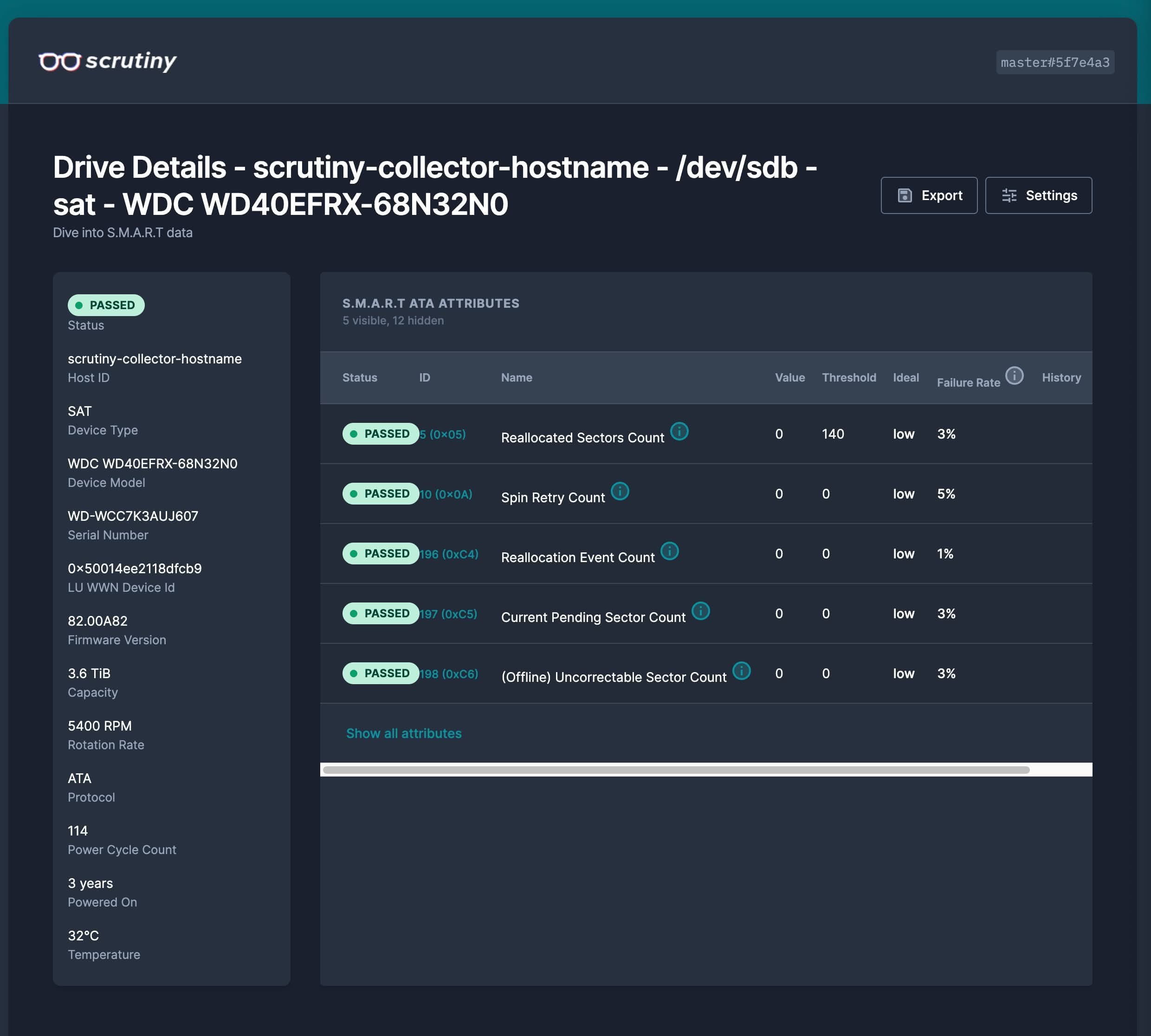
Te muestra los datos más críticos a tener en cuenta:
!Ojo! El Failure rate (tasa de fallos) se basa en datos proporcionados por BackBlaze. El valor actual del atributo se compara con las categorías de fallos observadas y se determina una tasa de fallos anual.
- Reallocated Sectors Count: Recuento de sectores reasignados. El valor sin procesar (raw) representa un recuento de los sectores defectuosos que se han encontrado y reasignado. Cuanto mayor sea el valor del atributo, más sectores habrá tenido que reasignar la unidad. Este valor se utiliza principalmente como métrica de la esperanza de vida de la unidad; una unidad que haya tenido alguna reasignación es mucho más propensa a fallar en los meses siguientes.
- Spin Retry Count: Recuento de reintentos de inicio de giro. Este atributo almacena el recuento total de reintentos de inicio de giro para alcanzar la velocidad operativa completa (en el caso de que el primer intento no haya tenido éxito). Un aumento en el valor de este atributo es indicativo de problemas en el subsistema mecánico del disco duro.
- Reallocation Event Count: Recuento de operaciones de reasignación. El valor sin procesar (raw) de este atributo muestra el recuento total de intentos de transferir datos desde sectores reasignados a un área de reserva. Se cuentan tanto los intentos exitosos como los fallidos.
- Current Pending Sector Count: Recuento de sectores «inestables» (en espera de ser reasignados debido a errores de lectura irrecuperables). Si posteriormente se lee correctamente un sector inestable, dicho sector se reasigna y este valor se reduce. Los errores de lectura en un sector no reasignan el sector inmediatamente; en su lugar, el firmware de la unidad recuerda que el sector debe reasignarse y lo reasignará la próxima vez que se escriba.
- Uncorrectable Sector Count: Recuento total de errores incorregibles al leer/escribir un sector. Un aumento en el valor de este atributo indica defectos en la superficie del disco y/o problemas en el subsistema mecánico.
Si empiezas a ver números mayores de 0 en estos datos, es momento de tener un backup de tus datos a mano para sustituir el disco duro.
Configuramos las notificaciones
Para configurar las notificaciones tienes muchas opciones: email, Discord, Telegram, pero yo me he quedado con Gotify, otro programa que tengo instalado en otro contenedor (y que tiene app para Android e iOS).
Para instalar Gotify solo tienes que crear otro stack y usar docker compose:
version: "3"
services:
gotify:
image: gotify/server
ports:
- 8182:80
environment:
- GOTIFY_DEFAULTUSER_PASS=
volumes:
- "/ruta/a/gotify:/app/data"- He cambiado el puerto 8080 por 8182 (estaba ocupado por otro servicio).
- Tienes que cambiar la ruta a donde quieras tener los archivos de Gotify en tu servidor.
Ahora, en la carpeta config de Scrutiny, creo el scrutiny.yaml para tener la conexión con Gotify y conseguir notificaciones (solo hay que descomentar la opción de Gotify).
- Cambias esta línea: – «gotify://IP_servidor_local:8182/tu_API»
# Commented Scrutiny Configuration File
#
# The default location for this file is /opt/scrutiny/config/scrutiny.yaml.
# In some cases to improve clarity default values are specified,
# uncommented. Other example values are commented out.
#
# When this file is parsed by Scrutiny, all configuration file keys are
# lowercased automatically. As such, Configuration keys are case-insensitive,
# and should be lowercase in this file to be consistent with usage.
######################################################################
# Version
#
# version specifies the version of this configuration file schema, not
# the scrutiny binary. There is only 1 version available at the moment
version: 1
notify:
urls:
# - "discord://token@webhookid"
# - "telegram://token@telegram?channels=channel-1[,channel-2,...]"
# - "pushover://shoutrrr:apiToken@userKey/?priority=1&devices=device1[,device2, ...]"
# - "slack://[botname@]token-a/token-b/token-c"
# - "smtp://username:password@host:port/?fromAddress=fromAddress&toAddresses=recipient1[,recipient2,...]"
# - "teams://token-a/token-b/token-c"
- "gotify://IP_servidor_local:8182/tu_API"
# - "pushbullet://api-token[/device/#channel/email]"
# - "ifttt://key/?events=event1[,event2,...]&value1=value1&value2=value2&value3=value3"
# - "mattermost://[username@]mattermost-host/token[/channel]"
# - "ntfy://username:password@host:port/topic"
# - "hangouts://chat.googleapis.com/v1/spaces/FOO/messages?key=bar&token=baz"
# - "zulip://bot-mail:bot-key@zulip-domain/?stream=name-or-id&topic=name"
# - "join://shoutrrr:api-key@join/?devices=device1[,device2, ...][&icon=icon][&title=title]"
# - "script:///file/path/on/disk"
# - "https://www.example.com/path"
########################################################################################################################
# FEATURES COMING SOON
#
# The following commented out sections are a preview of additional configuration options that will be available soon.
#
########################################################################################################################
#limits:
# ata:
# critical:
# error: 10
# standard:
# error: 20
# warn: 10
# scsi:
# critical: true
# standard: true
# nvme:
# critical: true
# standard: true
Hay que crear una app en Gotify y copiar la clave API. La utilizaremos en la línea correspondiente de scrutiny.yaml (descomentándola), poniendo la IP de nuestro servidor.
- Como puedes ver, también he instalado en otro contenedor, Diun, para que me avise en Gotify cuando hay actualizaciones de mis contenedores en Docker.
Ahora ya tienes en perfecto funcionamiento las notificaciones de Scrutiny en Gotify.
Como puedes ver, Scrutiny es un programa sencillo que hace una sola cosa muy bien: Controlar la salud de tus discos duros.
¿Tienes problemas para ver tus discos? Seguro que has configurado mal en Docker Compose la ruta del volumen. Compruébalo. ¿No funciona el cron? Si lo has instalado como yo, debería ejecutarse todos los días.
Configuración de Netdata para controlar, profundizar en todos los datos y hardware de tu Mini PC y servidor local
Netdata ya ofrece datos y alertas de todo lo que te puedas imaginar. Y tiene una ventaja: puedes consultar esos datos desde fuera de tu red local si te das de alta de forma gratuita en su servicio. Merece la pena. No es difícil instalarlo, pero analizar todos sus datos puede ser un desafío.
- Información instantánea y sin configuración
- Puede detectar anomalías, predecir problemas y automatizar el análisis.
- Puede supervisar con un uso mínimo de recursos y una escalabilidad máxima.
- Puedes mantener tus datos locales sin necesidad de una recopilación centralizada.
¿Qué puedes controlar con Netdata?
- Recursos del Sistema
- CPU, Memoria y recursos compartidos del sistema
- Almacenamiento
- Discos, puntos de montaje, sistemas de archivos, Arrays RAID
- Red
- Interfaces de red, protocolos, Firewall, etc.
- Hardware y sensores
- Ventiladores, temperaturas, controladores, GPUs, etc.
- Servicios del Sistema Operativo
- Recursos, Rendimiento y Estado (systemd en Linux)
- Procesos
- Recursos, rendimiento, OOM (Out Of Memory) y más
- Logs del Sistema y Aplicaciones
- systemd-journal (Linux), Windows Event Log (Windows)
- Conexiones de red.
- Sockets TCP y UDP en tiempo real por PID
- Contenedores
- Docker/containerd, LXC/LXD, Kubernetes, etc.
- Máquinas Virtuales (desde el host)
- KVM, qemu, libvirt, Proxmox (cgroups), Hyper-V
- Comprobaciones Sintéticas
- Test de APIs, Puertos TCP, Ping, certificados, etc.
- Aplicaciones empaquetadas
- nginx, apache, postgres, redis, mongodb y cientos más
- Infraestructura de proveedores Cloud
- AWS, GCP, Azure y más
- Aplicaciones personalizadas
- OpenMetrics, StatsD y próximamente OpenTelemetry
Vamos, todo lo que te puedas imaginar. El plan gratuito es muy generoso: puedes dar de alta hasta 5 nodos.
¿Cómo lo instalamos en Linux Mint? Con el script kickstart.sh en el Terminal. Tiene un pequeño configurador que puedes usar en su web. Yo lo he dejado así:
wget -O /tmp/netdata-kickstart.sh https://get.netdata.cloud/kickstart.sh && sh /tmp/netdata-kickstart.sh --stable-channel --disable-telemetryQuiero instalar el canal estable y no enviar datos. Luego lo he conectado a su nube mediante la GUI dándome de alta en Netdata Cloud y accediendo a Space Settings > Nodes > Add Node para obtener el Token.
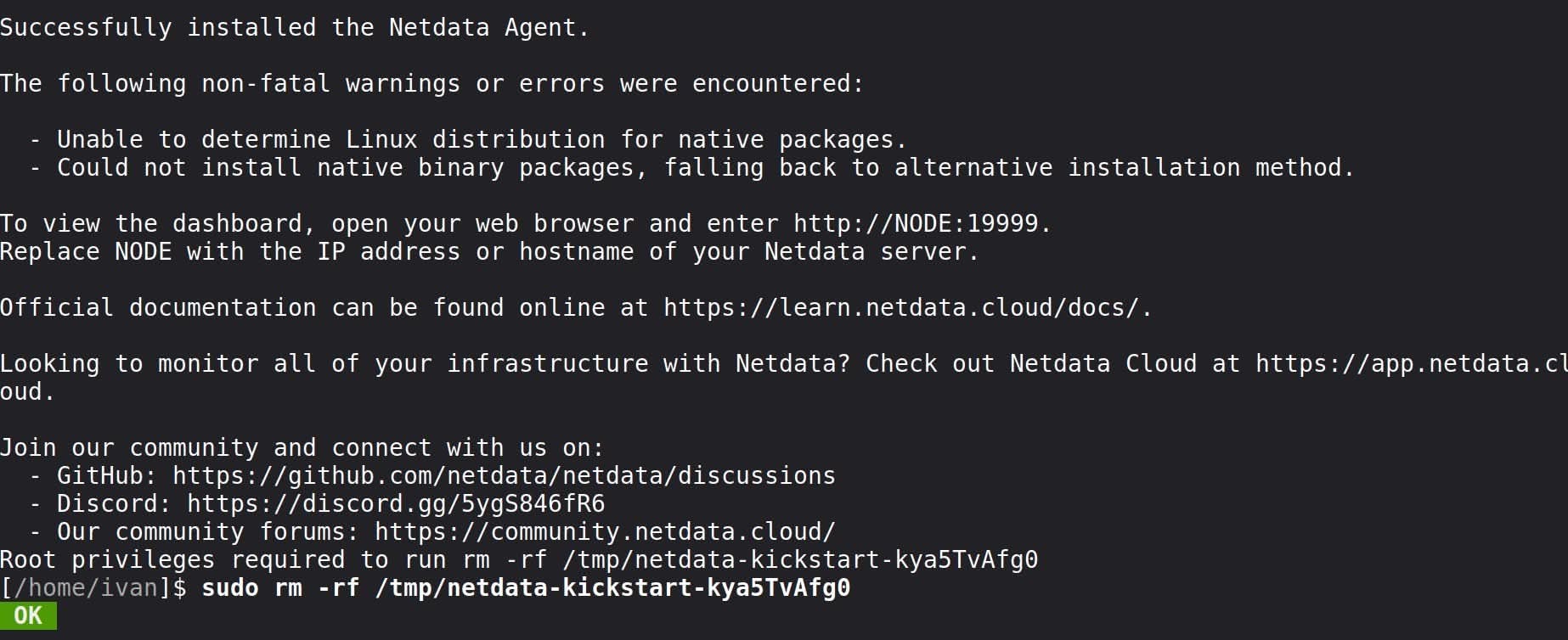
En cuanto pongas este comando en el terminal y lo ejecutes, empezará la instalación, que es automática. Revisará tu sistema y elegirá la mejor opción de instalación, en este caso, la estática.
- ¿Por qué no he usado la opción de Docker? Prefiero que este programa corra directamente en el sistema Linux para que todo tenga mejor acceso y no haya problemas.
¿Actualizaciones? En principio están activadas de forma automática, pero puedes usar esta orden:
wget -O /tmp/netdata-kickstart.sh https://get.netdata.cloud/kickstart.sh && sh /tmp/netdata-kickstart.shEn cuanto esté instalado, puedes acceder en esta url desde tu navegador: http://ip-servidor-local:19999. En ese momento, te podrás dar de alta en su cloud, o consultar sus datos como usuario anónimo. Te aconsejo que te des de alta. Es gratis y facilita mucho las cosas al proporcionarte alertas por correo, acceso a su app para notificaciones y más datos en sus estadísticas, como, por ejemplo, el control de los logs. Te inscriben en su plan pro como pruebo, pero luego te dan de baja automáticamente (o te das de baja tú mismo en cualquier momento).
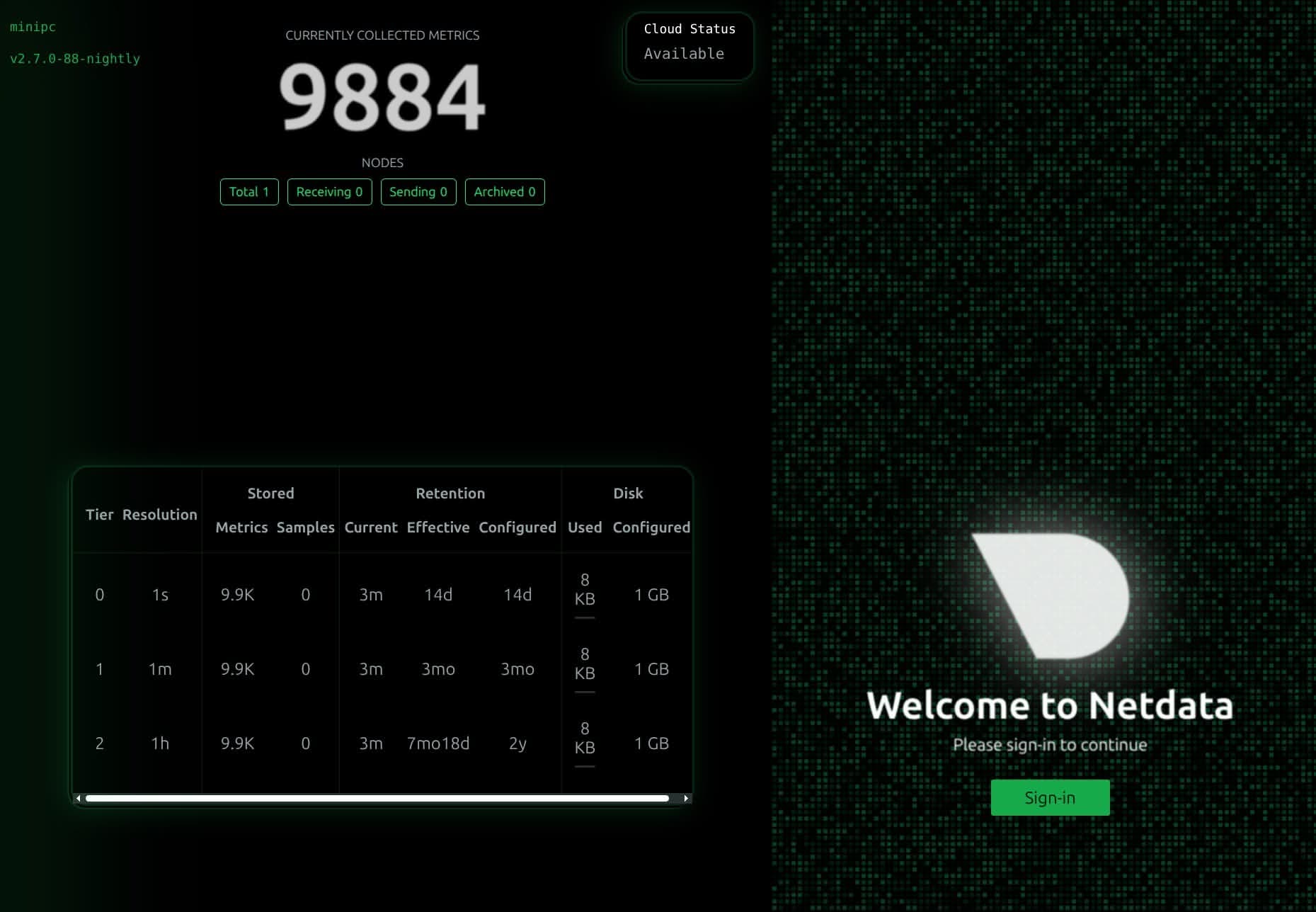
Le das a Sign-in y te das de alta con correo electrónico y contraseña. En cuanto lo hagas, te va a decir que sí confías en tu nueva instalación para añadirla al panel de control y te va a dar el comando con el token para activarla (también lo puedes hacer desde el panel de control después).
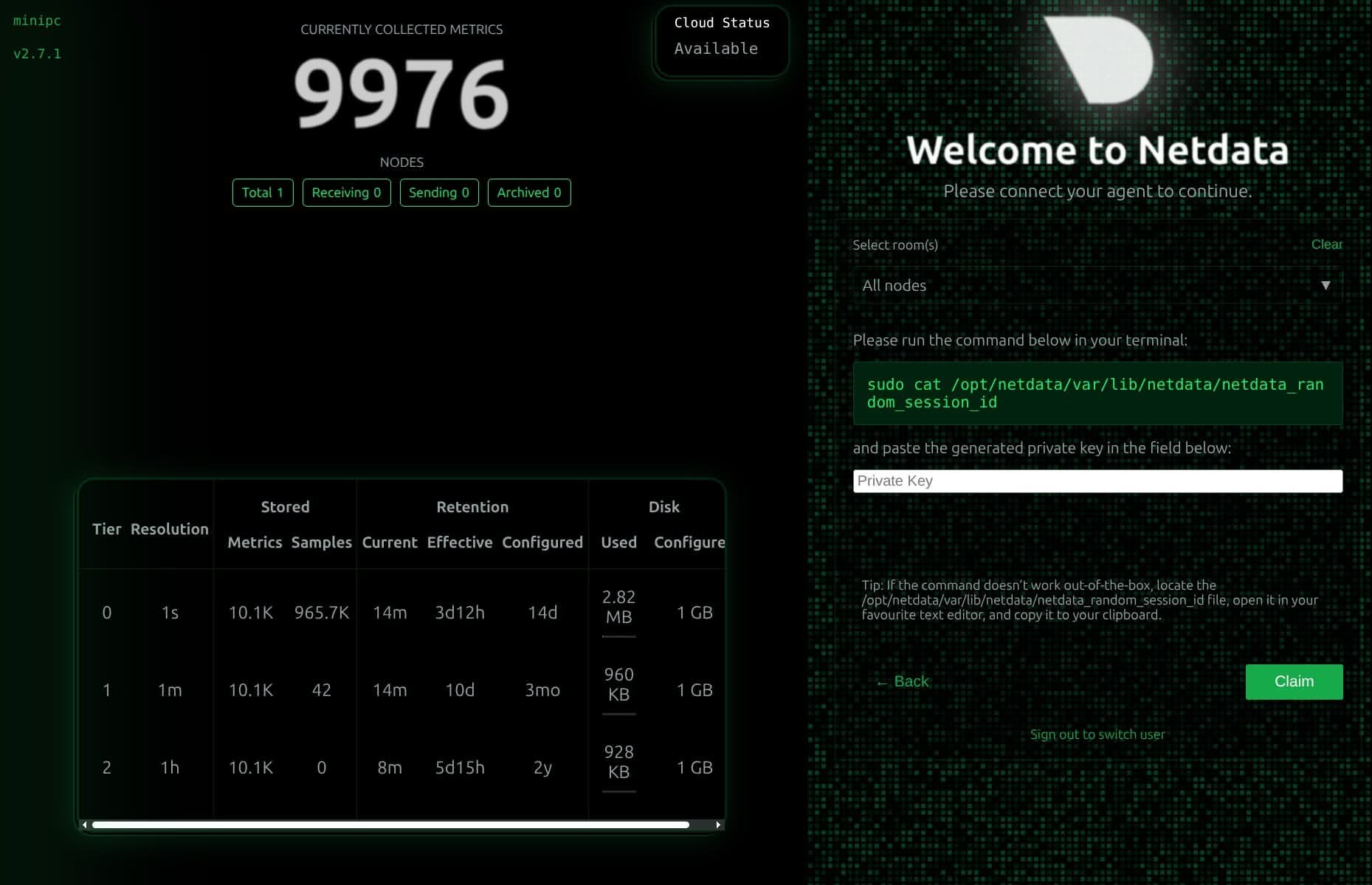
En cuanto entras, vas a poder ver el Santo Grial de las estadísticas para servidores y ordenadores en la pestaña Metrics. Fíjate bien:
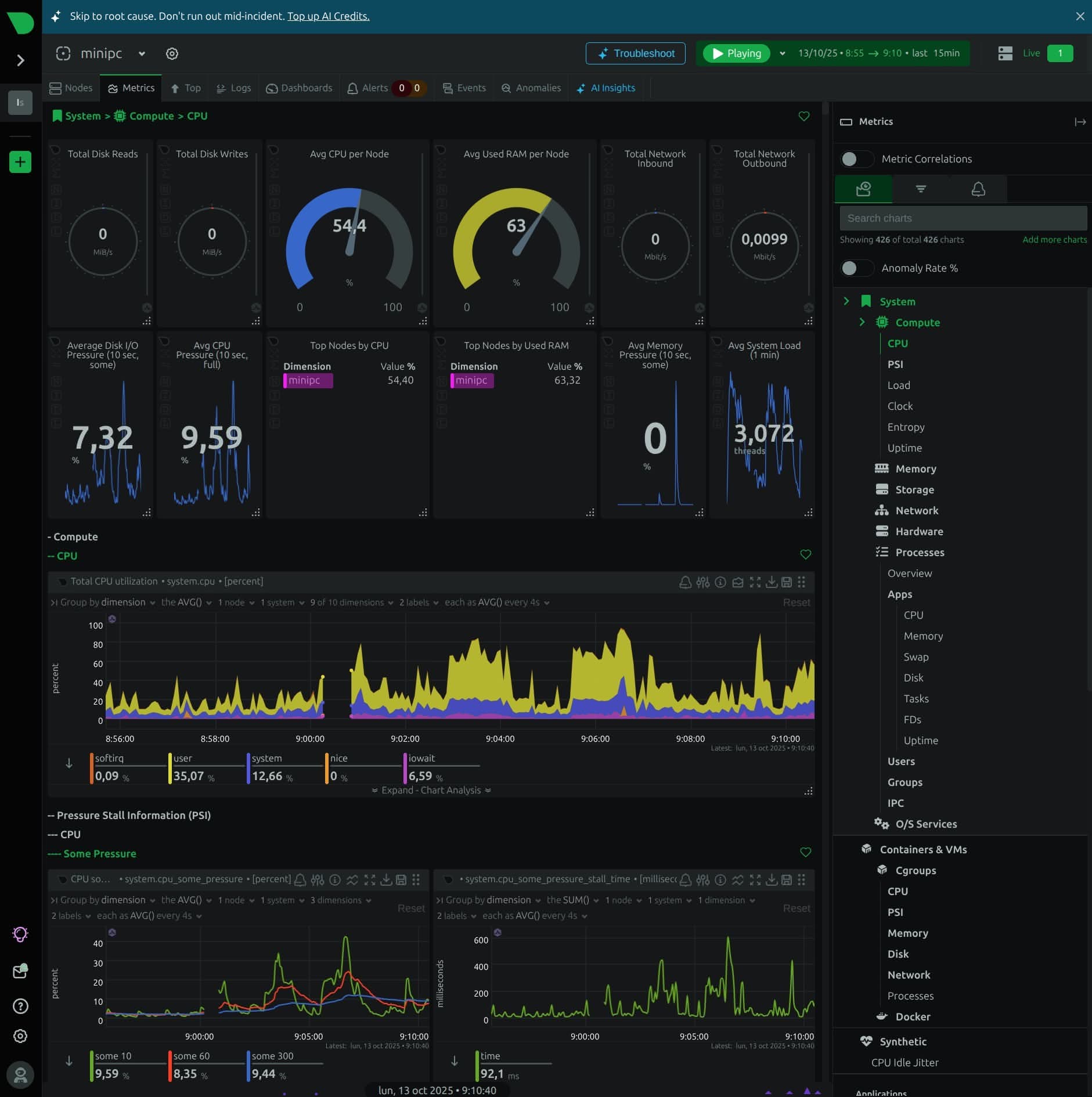
La barra de la derecha va a ser tu mejor amiga, ya que te va a permitir navegar por diferentes opciones como CPU, RAM, Storage… Y una muy interesante, que nos muestra las estadísticas de nuestros contenedores en Docker:
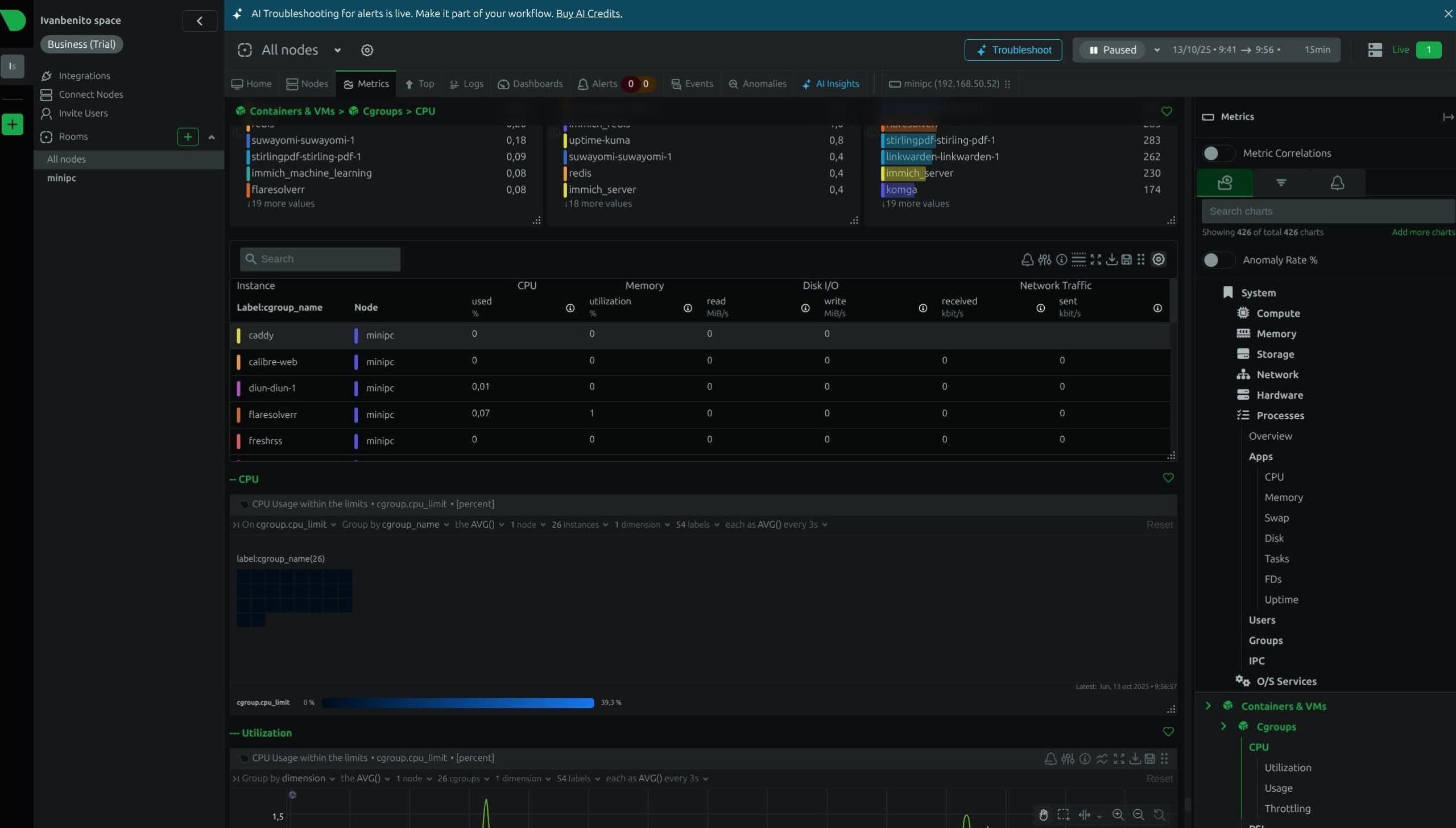
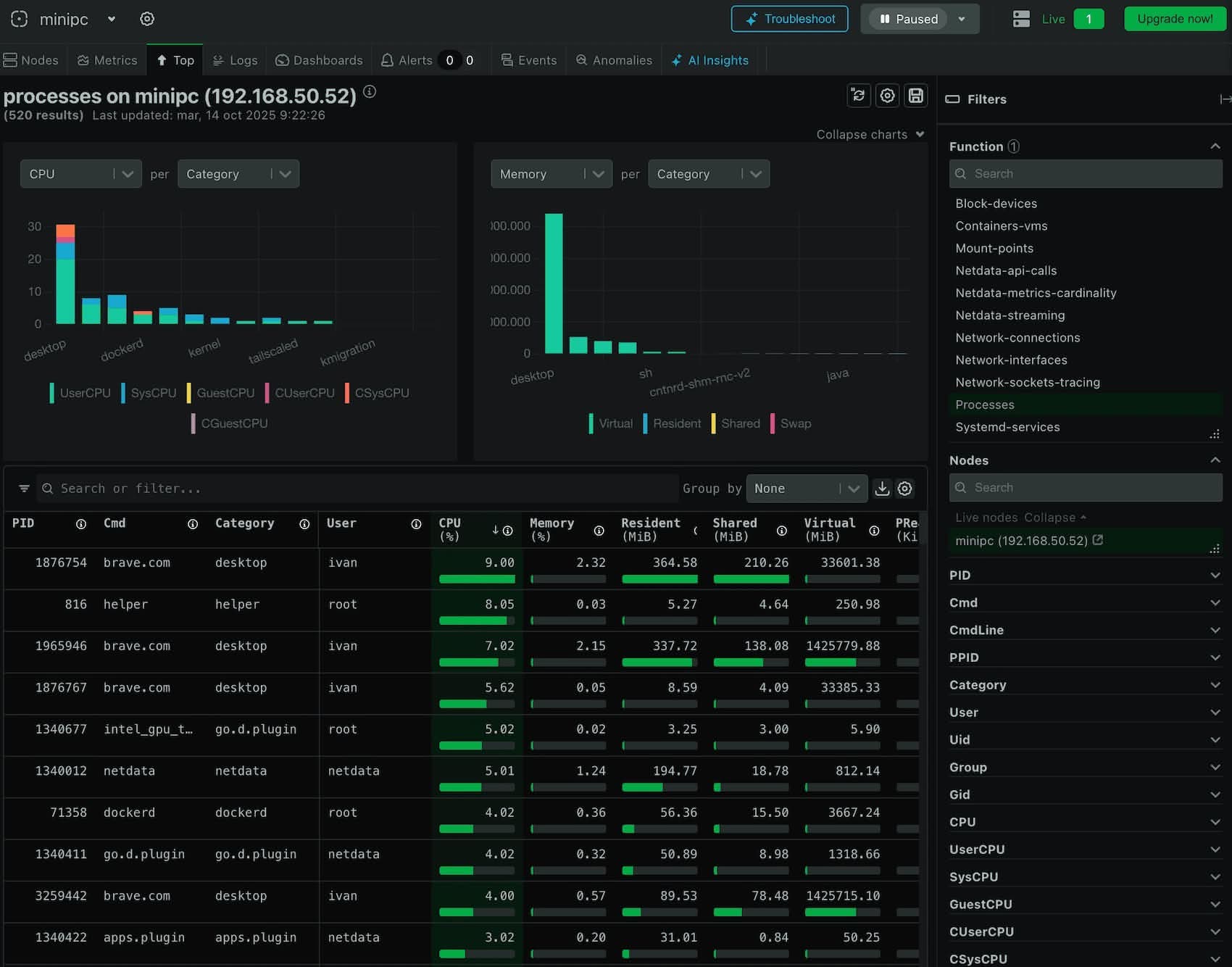
Si te has dado de alta, en la pestaña TOP verás algo equivalente a lo que te muestra el comando HTOP. Todos tus procesos corriendo en tu servidor local. Lo bueno que tiene usarlo en Netdata, es que con la barra derecha puedes filtrar fácilmente por diferentes categorías como PID, User, CPU.
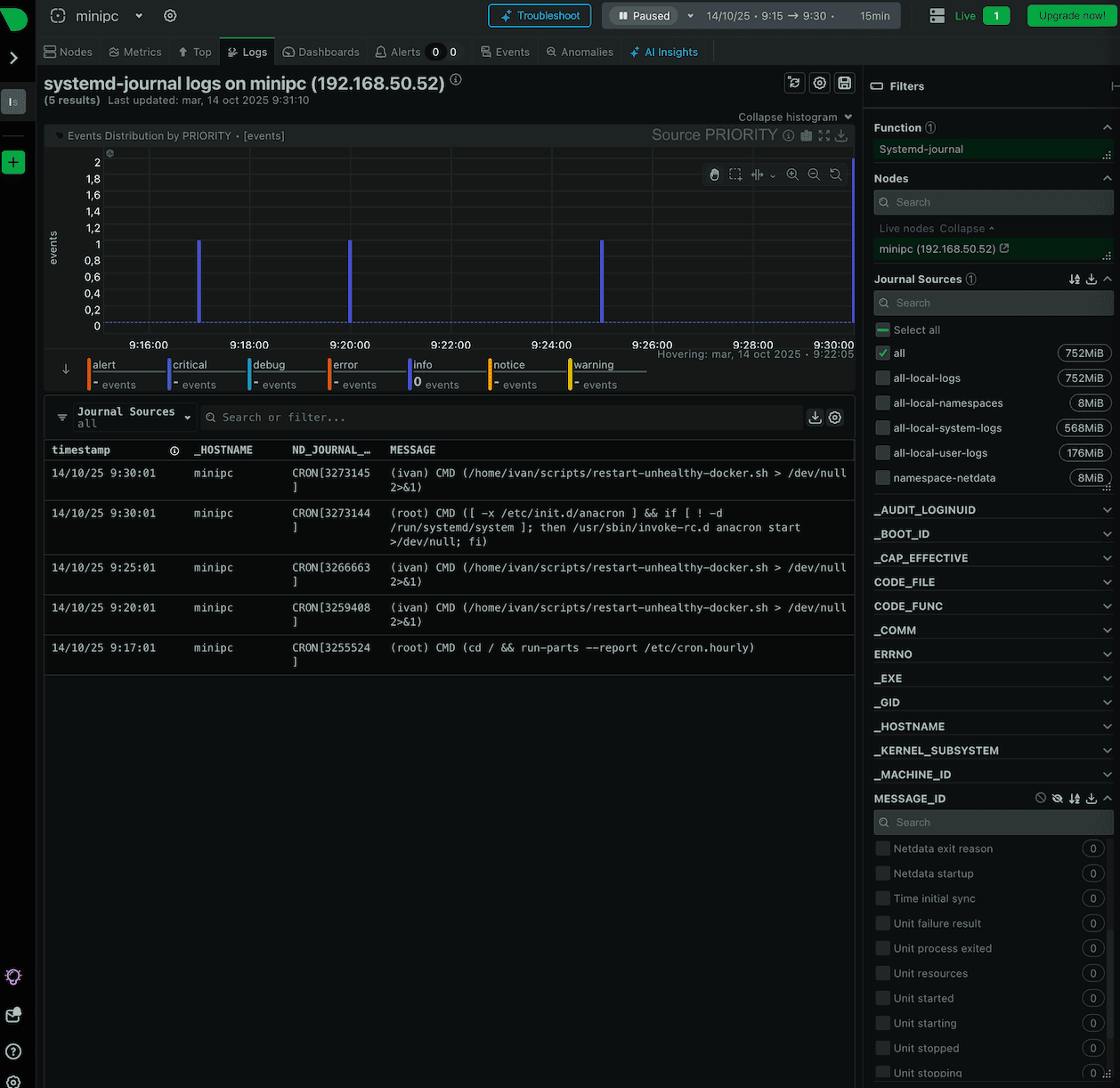
En la pestaña logs puedes consultar todos los logs del sistema, en este caso Linux Mint. La barra de la derecha te muestra las diferentes opciones que puedes encontrar y lo mejor de todo es que cada vez que hay un evento, te aparece marcado con el número de incidencias, por ejemplo, de error, info o notice. Es una forma sencilla de consultar los logs de manera muy visual:
En la pestaña alerts, te mostrará las alteras del servidor, posibles problemas que se hayan detectado en las que estén configuradas, que por defecto son 70 (cubren cosas como almacenaje en discos, contendedores Docker en mal funcionamiento, exceso de uso de CPU:
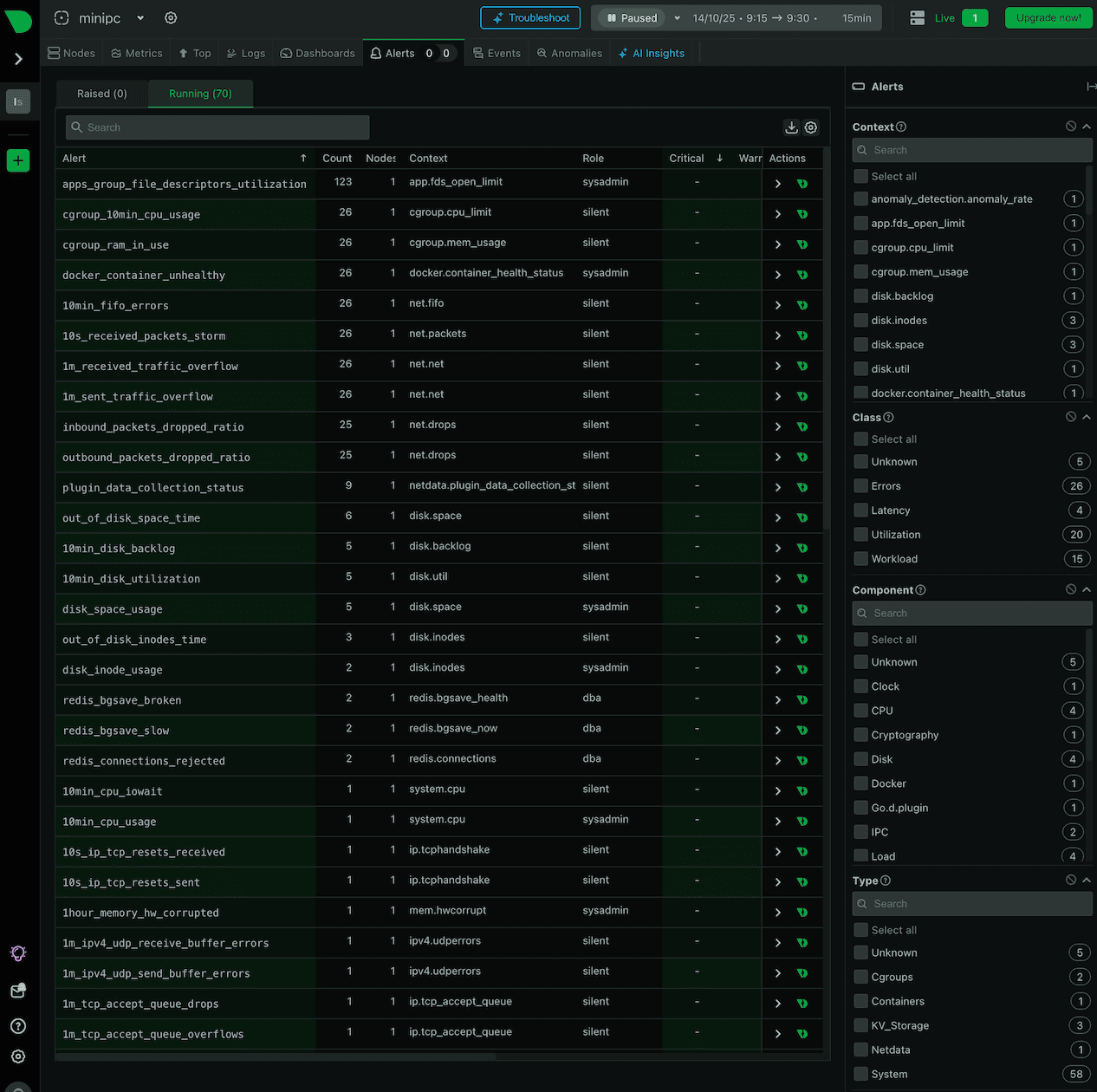
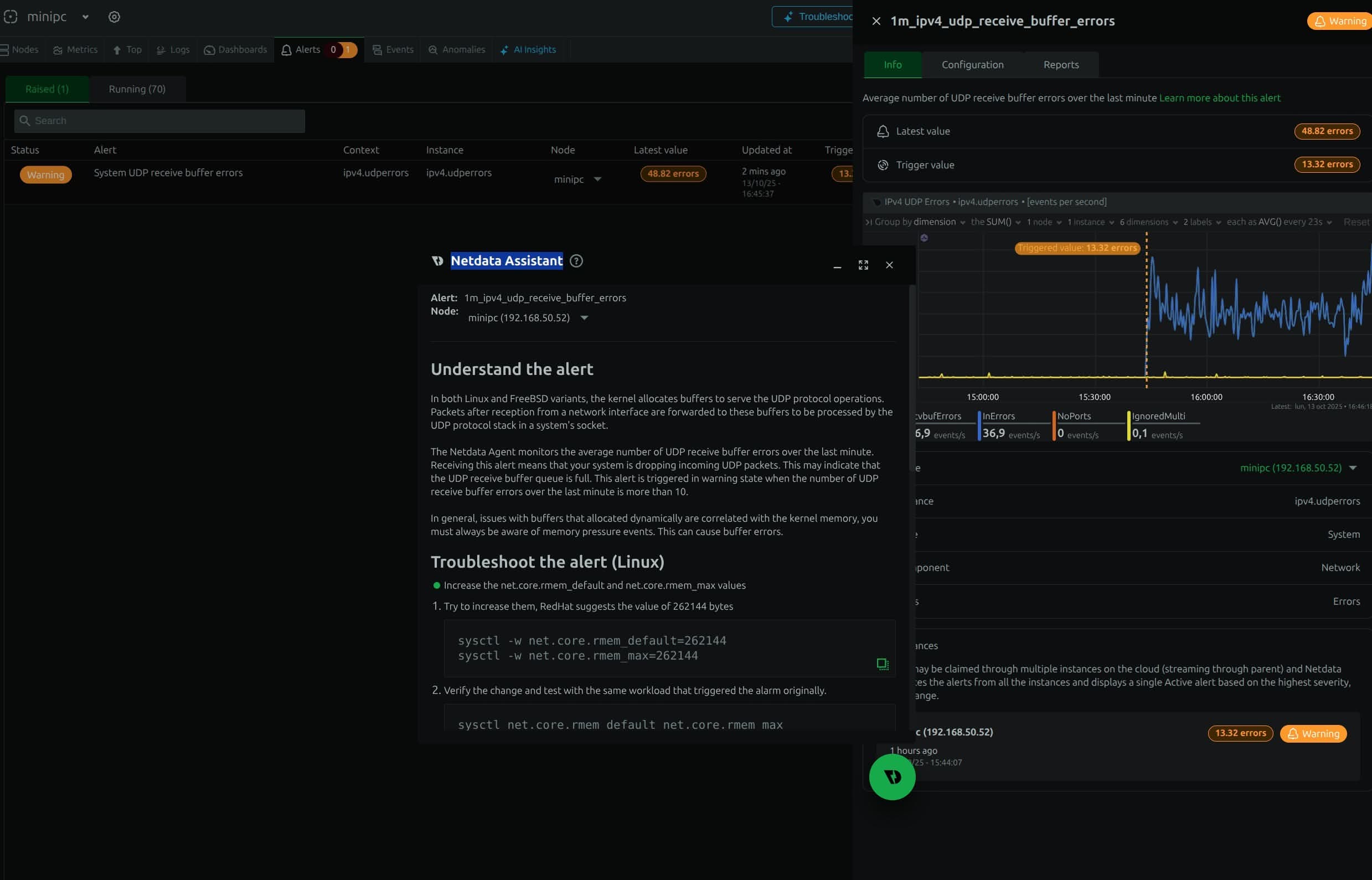
¿Qué tienen de bueno estas alertas? ¡Qué te proponen una solución! Fijate en la que me enviaron ami para modificar unos parámetros del Kernel que estaban funcionando mal (red)
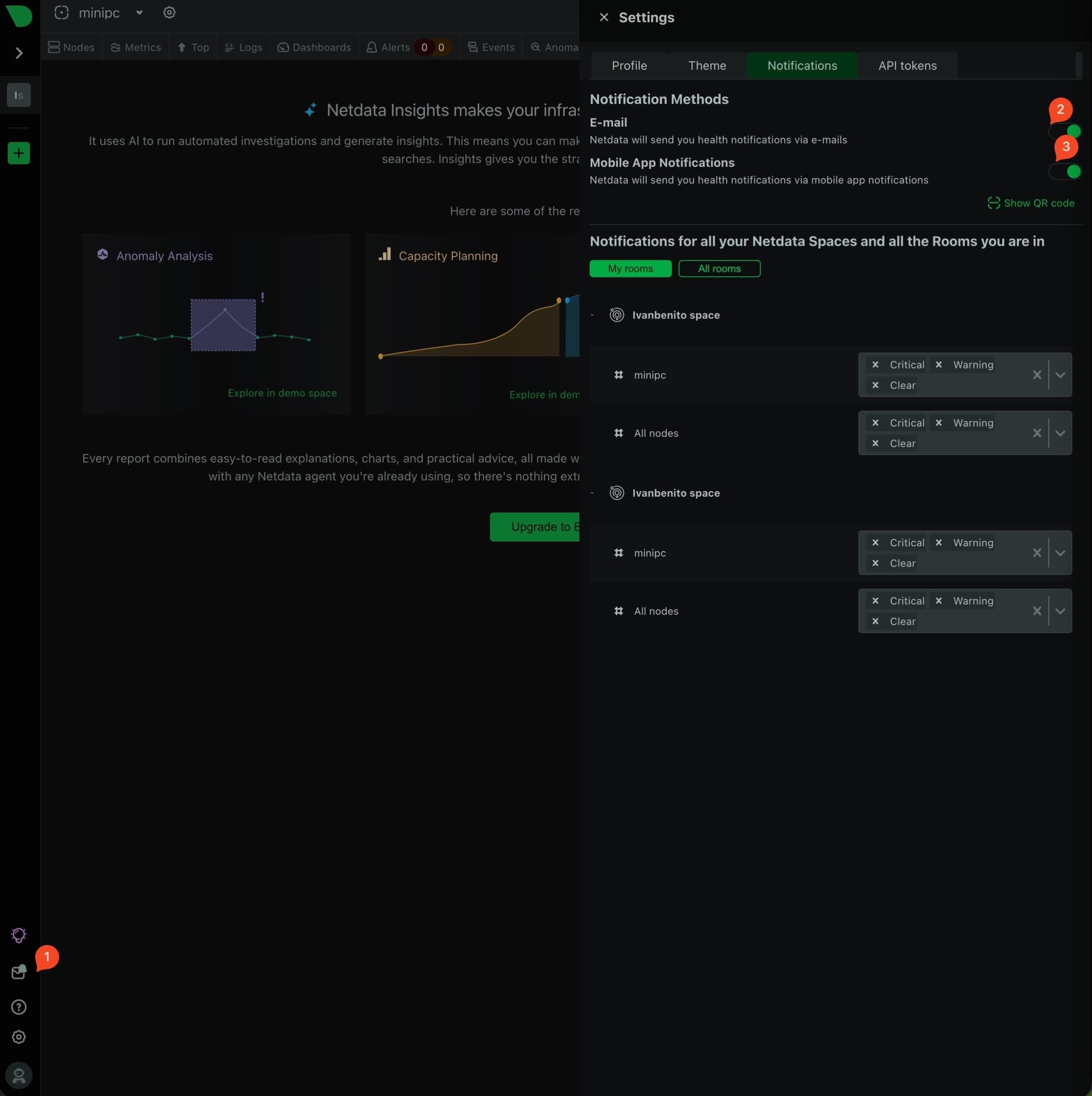
Más cosas importantes: en la barra pequeña de la parte izquierda de la interfaz, tienes un icono de Notificaciones donde puedes configurar las notificaciones por email (activas por defecto) y las de la app para iOS y Android. Esta segunda opción no está activa. Tienes que descargarte la app y escanear el codigo QR que te muestra en la interfaz para vincularlas.
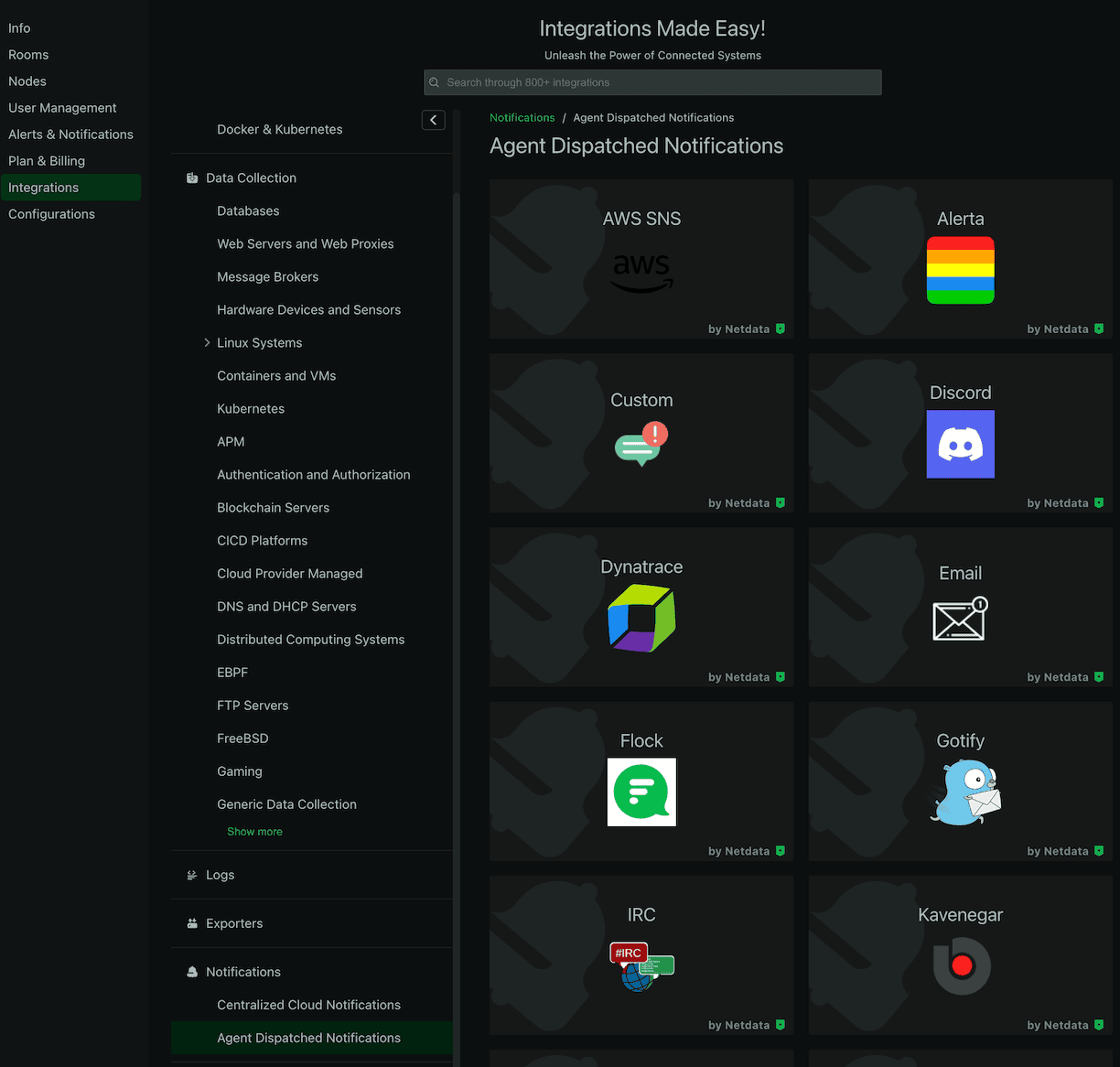
Por último, en el engranaje inferior de esa barra puedes acceder a las integraciones de Netdata por si quieres configurarlas. Muchas están en el plan de pago.
No sé si te has dado cuenta, pero lo mejor de Netdata es que todo funciona después de instalarlo sin que tengas que hacer casi nada, una bendición.
¿Gasta mucha RAM o CPU del sistema? Pues por ahora no. Es mínimo su impacto en tu sistema.
¿Quieres cambiar un poco la configuración de Netdata en Linux Mint? Tienes que editar el archivo:
sudo nano /opt/netdata/etc/netdata/netdata.confEn este archivo puedes activar o desactivar los diferentes plugins de la app o cambiar su configuración.
En /opt/netdata/usr/lib/netdata/conf.d tienes más archivos de configuración, incluido, health_alarm_notify.conf, donde puedes cambiar parámetros de los avisos.
¿Más cosas que puedes hacer? Configurar tú mismo alertas de funcionamiento para programas como Navidrome, Jellyfin o Immich (además de las que vienen por defecto para Docker).
Conclusión
Con Scrutiny y Netdata, tenemos bien cubierto el análisis de nuestro hardware, notificaciones de errores y funcionamiento en general de nuestro servidor local. Ambos programas se instalan fácilmente y son fáciles de mantener, incluso sin experiencia previa… Y puedes aprender mucho de tu sistema.
Scrutiny: para controlar la salud de discos de duros.
Netdata: diagnóstico de todo el sistema.
¿Utilizas otras herramientas para controlar tu Mini PC? Déjame un comentario.
